
Java容器类
容器的概念
为什么要使用集合框架(Why)
如果并不知道程序运行时会需要多少个对象,或者需要更复杂的存储对象--可以使用 Java 集合框架
Java 集合框架包含的内容
Java 集合框架提供了一套性能优良、使用方便的接口和类,它们位于 java.util 包中
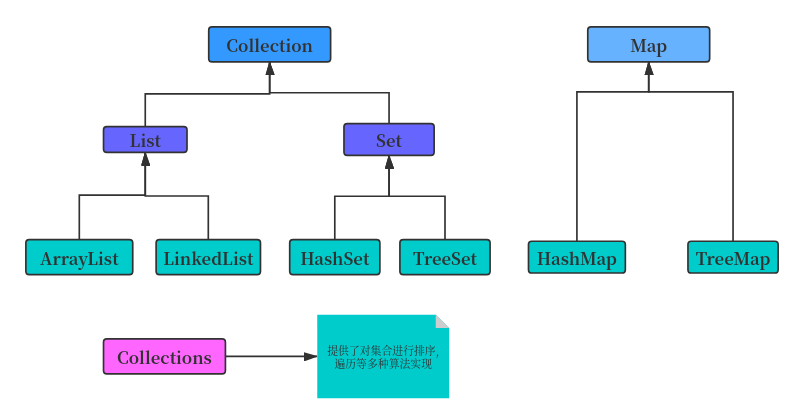
Collection 接口
Collection 接口存储一组不唯一,无序的对象
Collection c1 = new ArrayList();
collection1.add("x");
collection1.add("y");
collection1.add("s");
collection1.add("y");
collection1.add("c");
collection1.add("x");
System.out.println(c1);
输出结果如下
[x, y, s, y, c, x]
这里输入结果是不唯一,有序的 ,因为我 new 的是 List 接口的实现类,有序是 List 接口的特性
Set 接口存储唯一,无序对象,无序是 Set 接口的特性. List 和 Set 的特性完全相反.
在此仅体现了 Collection 接口存储对象的不唯一性.
集合作为容器应该具有的功能(增删改查)
Collection 接口的一些常见方法列表如下
我对这些常见常用的 API 方法进行了简单分类,集合的基本操作:增加,删除,判断,取出
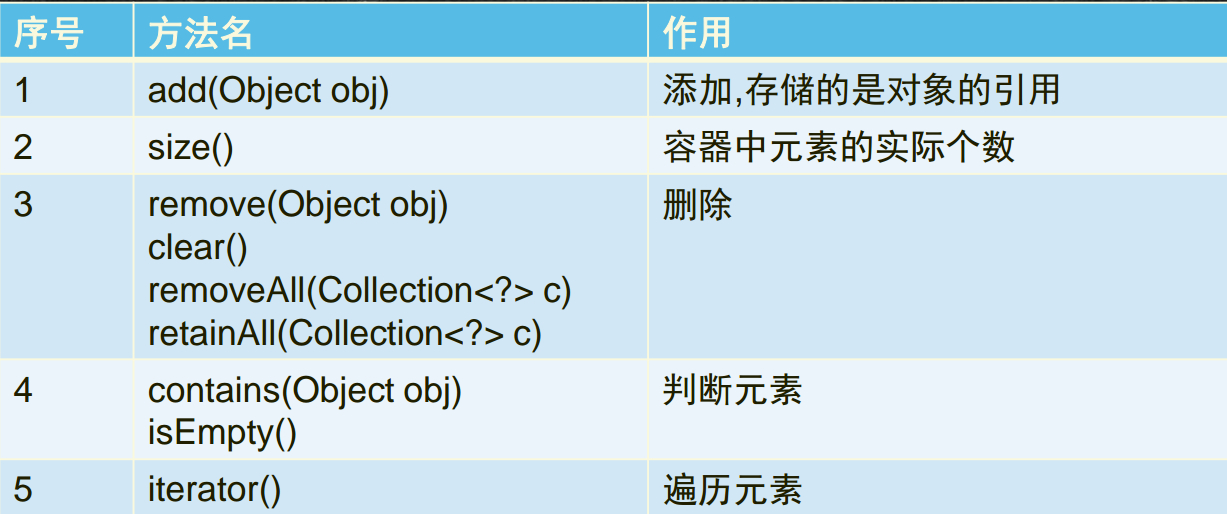
添加
add():要求传入的参数是Object对象,因此当写入基本数据类型的时候,包含了自动拆箱和自动装箱的过程
addAll(): 添加另一个集合的元素到此集合中
删除
clear(): 只是清空集合中的元素,但是此集合对象并没有被回收
remove(): 删除指定元素
removeAll():删除集合元素
retainAll():仅保留那些包含指定集合的元素(删除指定集合元素之外的所有元素), 如果原集合有变动则返回 true,否则返回false
查询
contains(): 判断集合中是否包含指定的元素值
containsAll():判断此集合中是否包含另一个集合
isEmpty():判断集合是否为空
其它
toArray():将集合转换成数组
List 接口
List 接口存储一组不唯一,有序(插入顺序)的对象
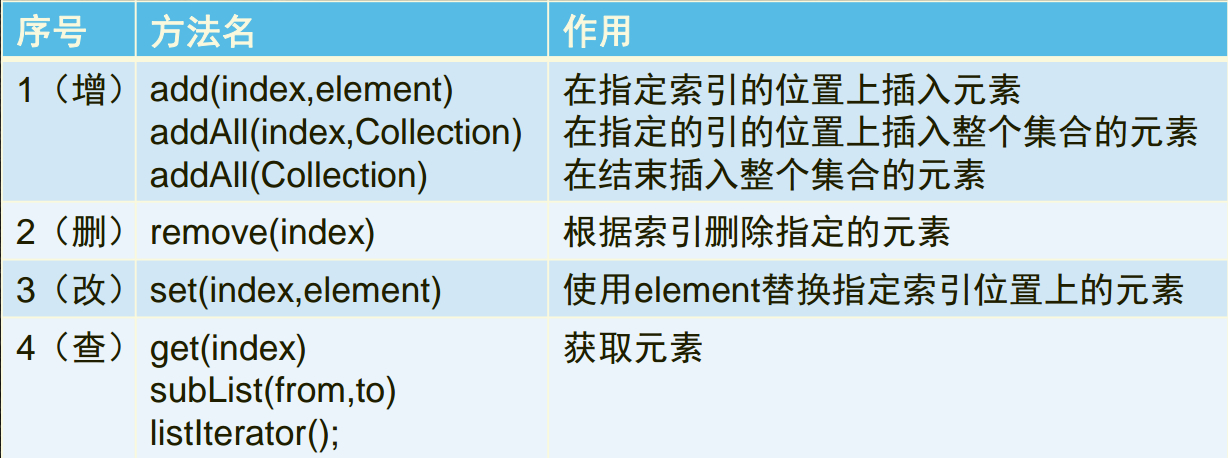
List 接口特有的方法
凡是可以操作索引的方法都是该体系特有的方法
|
ArrayList
ArrayList 实现了长度可变的数组,在内存中分配连续的空间.
ArrayList 优点
遍历元素和随机访问元素的效率比较高
ArrayList 缺点
添加和删除需要大量移动元素,效率低,按照内容查询效率低
ArrayList 面试问题
ArrayList 和 Vector 的区别是什么?
- ArrayList 是线程不安全的,效率高,Vector 是线程安全的效率低
- ArrayList 在进行扩容的时候,是当前容量的 1.5 倍,而 Vector 扩容的时候是扩容到当前容量的 2 倍
LinkedList 采用链表存储方式
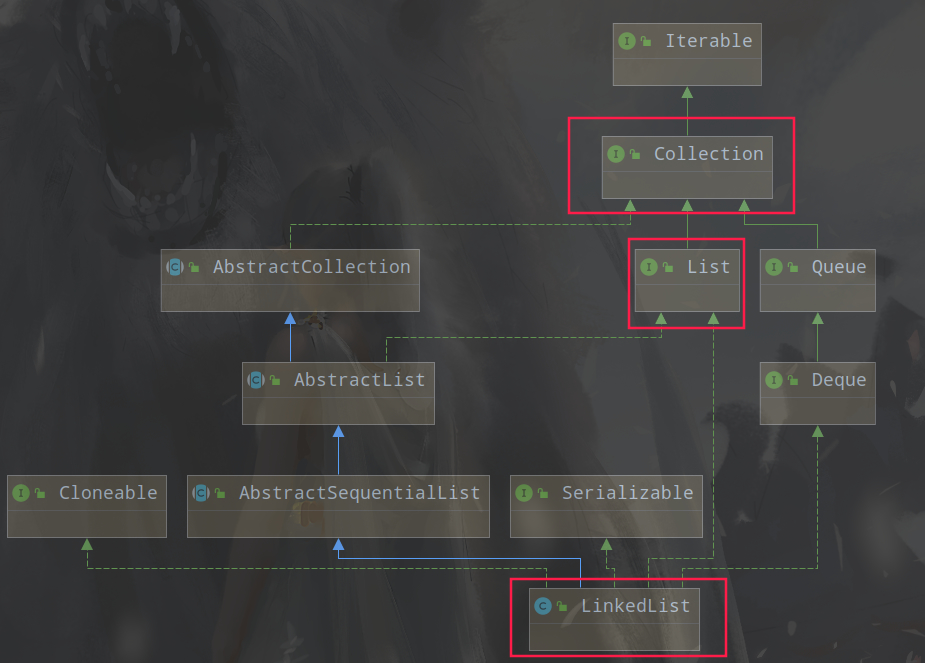
LinkedList 采用链表存储方式,也就是说链表的优缺点 LinkedList 全具备,如果你具备一定的数据结构基础,相信学起来会非常友好. 数组和链表的区别与优缺点
linkedList 特有的方法
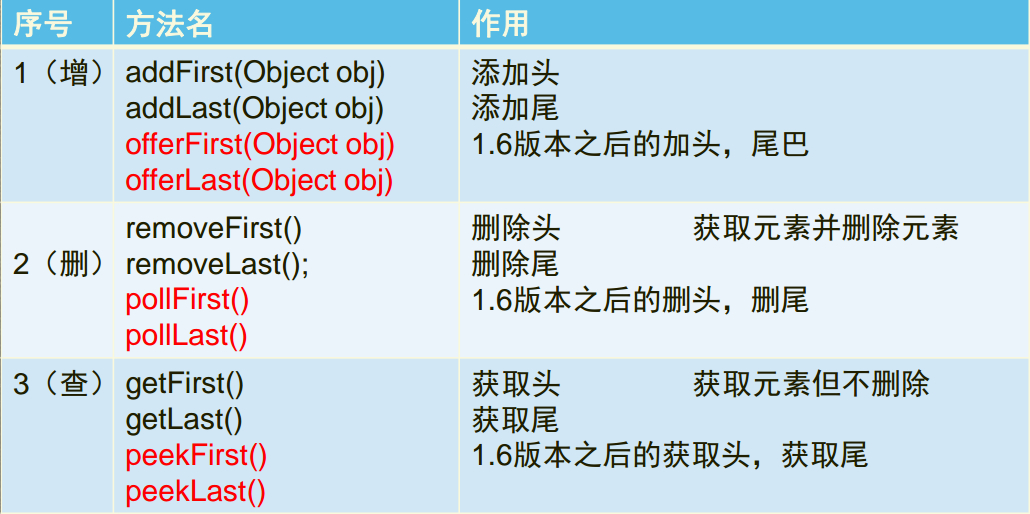
LinkedList 优点
插入、删除元素时效率比较高
LinkedList 缺点
遍历和随机访问元素效率低下
ArrayList 和 LinkedList 对比
- ArrayList
- 遍历元素和随机访问元素的效率比较高
- 插入、删除扥操作频繁时性能低下
- LinkedList
- 插入、删除时元素效率较高
- 查找效率较低
Set 接口
- Set 接口存储一组唯一,无序的对象
- (存入和取出的顺序不一定一致)
- 操作数据的方法和 List 类似,**Set 接口不存在 get()**方法
Set 接口中的实现类
- HashSet:采用 Hashtable 哈希表存储结构
- 优点:添加速度快,查询速度快,删除速度快
- 缺点:无序
- LinkedHashSet
- 采用哈希表存储结构,同时使用链表维护次序
- 有序(添加顺序)
- TreeSet
- 采用二叉树(红黑树)的存储结构
- 优点:有序(排序后的升序)查询速度比 List 快
- 缺点:查询速度没有 HashSet 快
什么是 Hash 表
哈希表(Hash table,也叫散列表),具有像数组那样根据随机访问的特性,是根据关键码值(key-value)而进行访问的数据结构.也就说,它通过把关键码映射到表中的一个位置来访问记录,以加快查找速度.这个映射函数叫做散列函数,存放记录的数组叫做散列表.
Hash Table 的查询速度非常的快,几乎是 O(1)的时间复杂度.
hash 函数就是找到一种数据内容和数据存放地址之间的映射关系.

HashSet
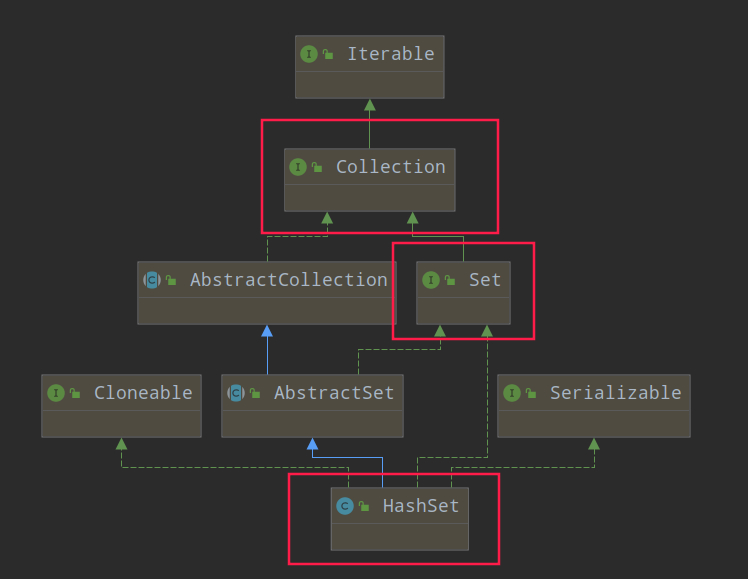
HashSet 集合不允许存储相同的元素, 它底层实际上使用 HashMap 来存储元素的, 不过关注的只是 key 元素, 所有 value 元素默认为 Object 类对象.
当使用无参构造创建 HashSet 对象时, 其实调用了 HashMap 的无参构造创建了一个 HashMap 对象, 所以 HashSet 的初始化容量也为 16, 负载因子也为 0.75.
HashSet 实现了 Set 接口, 仅存储对象
代码验证 HashSet 的无序性和唯一性
HashSet hashSet = new HashSet();
hashSet.add("b");
hashSet.add("b");
hashSet.add("c");
hashSet.add("耗子尾汁");
hashSet.add("Fedeline");
hashSet.add("雪月书韵茶香");
System.out.println(hashSet);
[耗子尾汁, b, c, Fedeline, 雪月书韵茶香]
hashSet 存储自定义对象
如果我们需要使用 HashSet 存储自定义对象,我们需要重写 hashCode 方法与 equals 方法
HashSet hs=new HashSet();//创建HashSet对象
hs.add(new Person("张三",20));
hs.add(new Person("李四",22));
hs.add(new Person("王五",23));
hs.add(new Person("李四",22));
- HashSet 存储进了相同的对象,不符合实际情况
- 解决方案
- 重写 equals 方法和 hashCode 方法
- 不重写的后果
- 自定义对象会调用父类的 hashCode 方法对自定义对象内存地址的比对,hashSet 的唯一性将失效
public int hashCode() {
System.out.println(this.name+".....hashCode");
return this.name.hashCode()+age;
}
HashSet 是如何保证元素的唯一性?
HashSet 是通过元素的两个方法,HashCode 和 equals 方法来完成
如果元素的 HashCode 值相同,才会判断是否为 true
如果元素的 hashCode 值不同,不会调用 equals 方法
LinkedHashSet
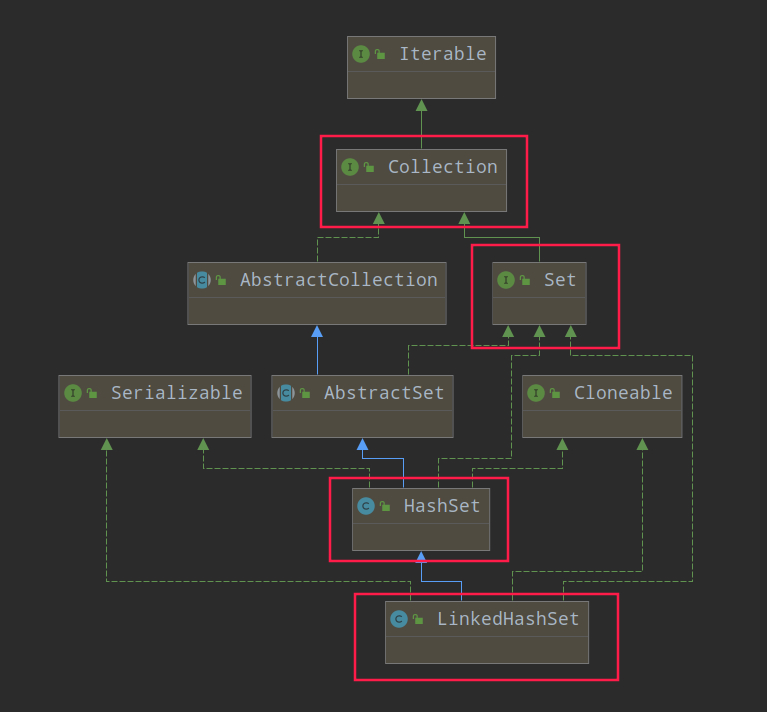
TreeSet
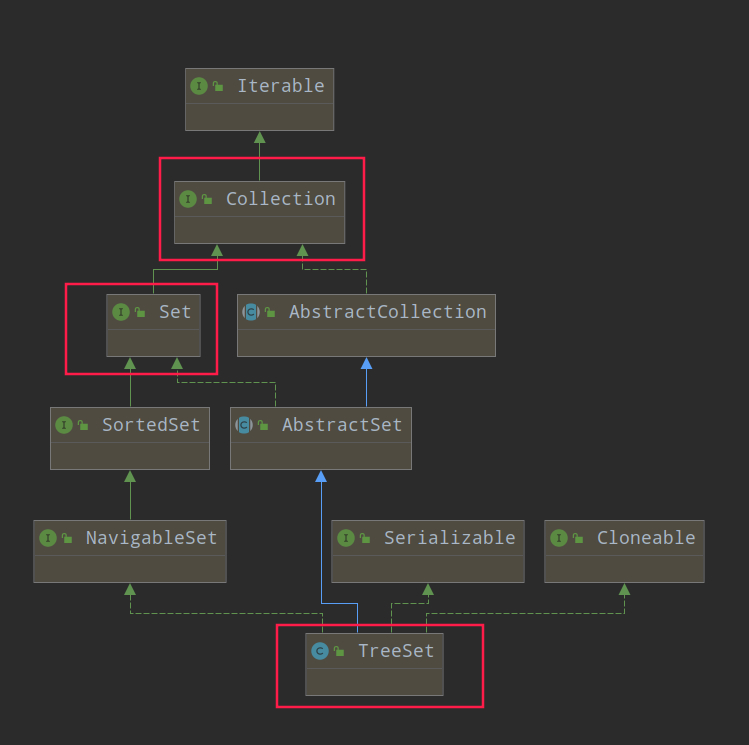
- TreeSet 是 Set 接口的实现子类,因此具备 Set 接口的唯一性,并具备有序的特点
- TreeSet 底层实现的是 TreeMap,利用红黑树来进行实现
- 设置元素的时候,如果是自定义对象,会查找对象中的 equals 和 hashCode 方法,如果没有,比较的是内存地址
- 树中的元素是要默认进行排序操作的,如果是基本数据类型,自动比较,如果是引用类型,需要自定义比较器
- 比较器分类
- 内部比较器
- 定义在元素的类中,通过实现 Comparable 接口来实现
- 外部比较器
- 定义在当前类中,通过实现 Comparator 接口来实现
- 外部比较器可以定义成一个工具类,此时所有需要比较的规则如果一样的话可以复用
- 内部比较器局限性较大,多种自定义元素都需要进行比较时候,需要在每种自定义元素类中编写代码
- 如果外部比较器和内部比较器同时存在,外部比较器优先被使用
- 当使用比较器时候不会调用 equals 方法
- 内部比较器
- 比较器分类
TreeSet 存放自定义类型示例代码
package cn.xysycx.collection;
public class Person implements Comparable {
private String name;
private int age;
public int compareTo(Object o) {
Person person = (Person) o;
if (person.name.length()>this.name.length()){
return -1;
}else if (person.name.length()<this.name.length()){
return 1;
}
return 0;
}
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
package cn.xysycx.collection;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo implements Comparator<Person> {
public int compare(Person o1, Person o2) {
if (o1.getAge()>o2.getAge()){
return -1;
}else if (o1.getAge()<o2.getAge()){
return 1;
}
return 0;
}
public static void main(String[] args) {
TreeSet treeSet=new TreeSet();
treeSet.add(new Person("lisi",13));
treeSet.add(new Person("zhangsan",15));
treeSet.add(new Person("maliu",17));
treeSet.add(new Person("wansi",15));
treeSet.add(new Person("liubai",19));
System.out.println(treeSet);
System.out.println("----------------------------");
TreeSet treeSet1=new TreeSet(new TreeSetDemo());
treeSet1.add(new Person("lisi",13));
treeSet1.add(new Person("zhangsan",15));
treeSet1.add(new Person("zhangsan1",15)); //比较器返回0 会去重,此条数据不会被加入treeSet
treeSet1.add(new Person("maliu",17));
treeSet1.add(new Person("wansi",15));
treeSet1.add(new Person("liubai",19));
System.out.println(treeSet1);
}
}
[Person{name='lisi', age=13}, Person{name='maliu', age=17}, Person{name='liubai', age=19}, Person{name='zhangsan', age=15}]
----------------------------
[Person{name='liubai', age=19}, Person{name='maliu', age=17}, Person{name='zhangsan', age=15}, Person{name='lisi', age=13}]
采用二叉树(红黑树)的存储结构
TreeSet 优点
有序(排序后的升序)查询速度比 List 快
TreeSet 缺点
查询速度没有 HashSet 快
Map
map 特点:key-value 映射
举例:session 存储键值对 redis 存储键值对 JSON 也是键值对格式 HBase 存储键值对
Map 接口特有的方法
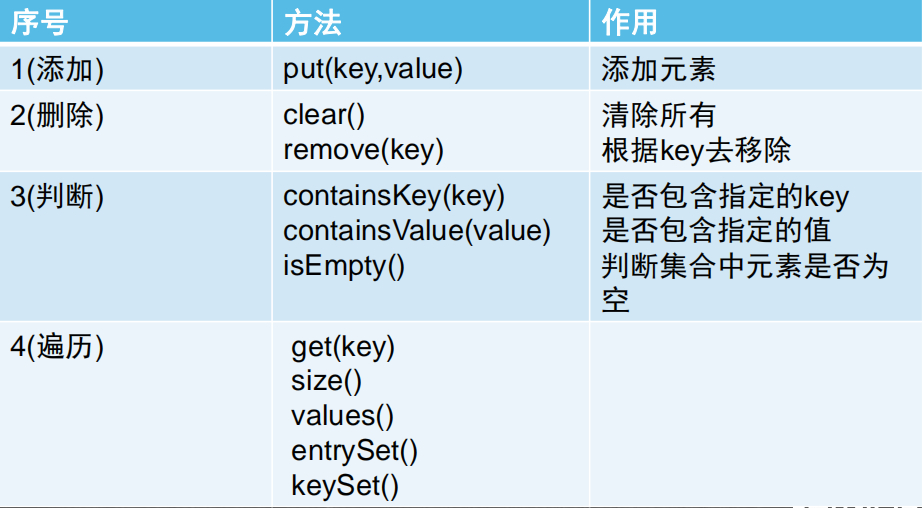
Map 的实现子类
- HashMap
- LinkedhashMap
- TreeMap
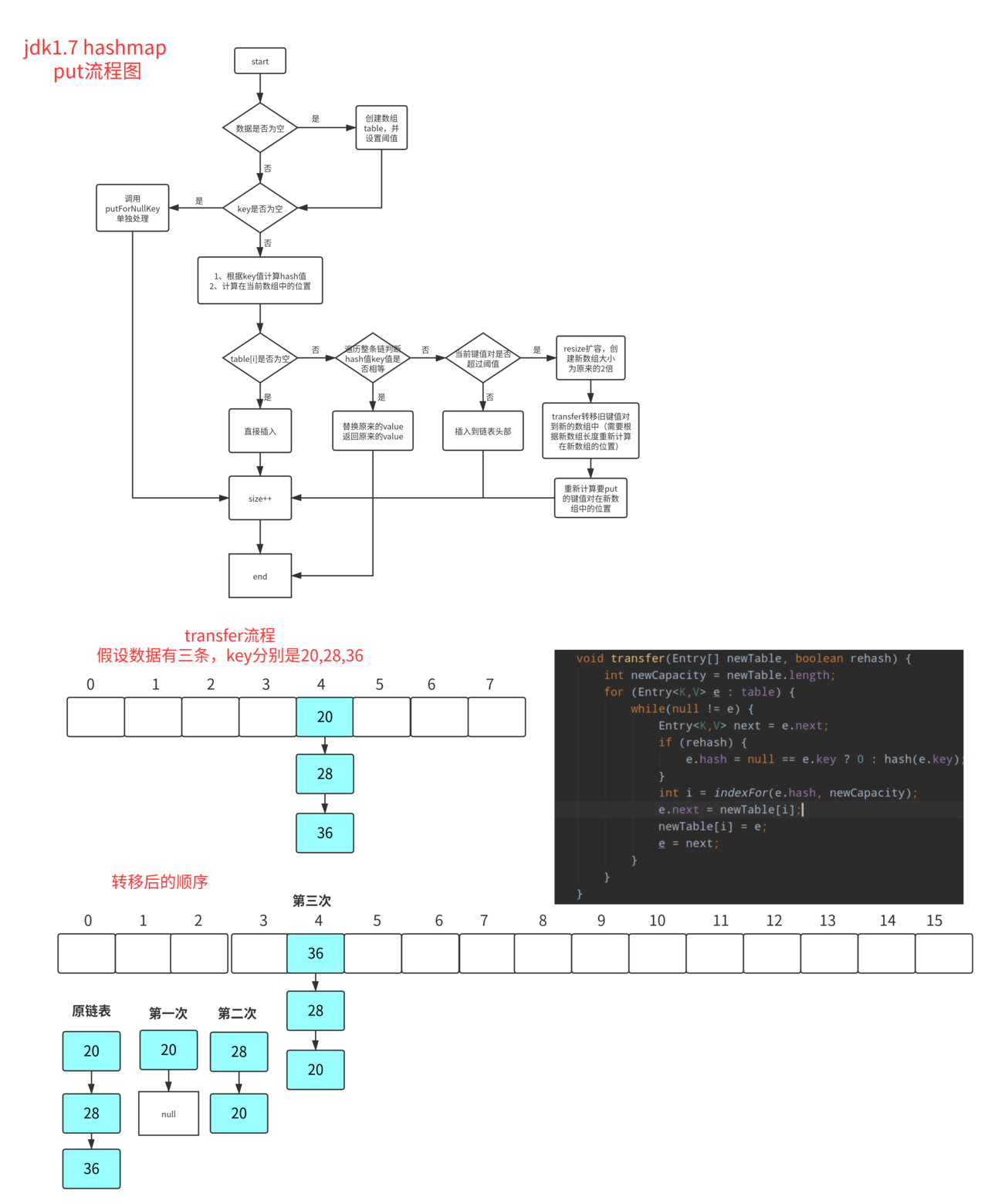
HashMap(重点)
HashMap 底层
- 数组 + 链表(JDK1.7)
- 数组 + 链表 + 红黑树(JDK1.8)
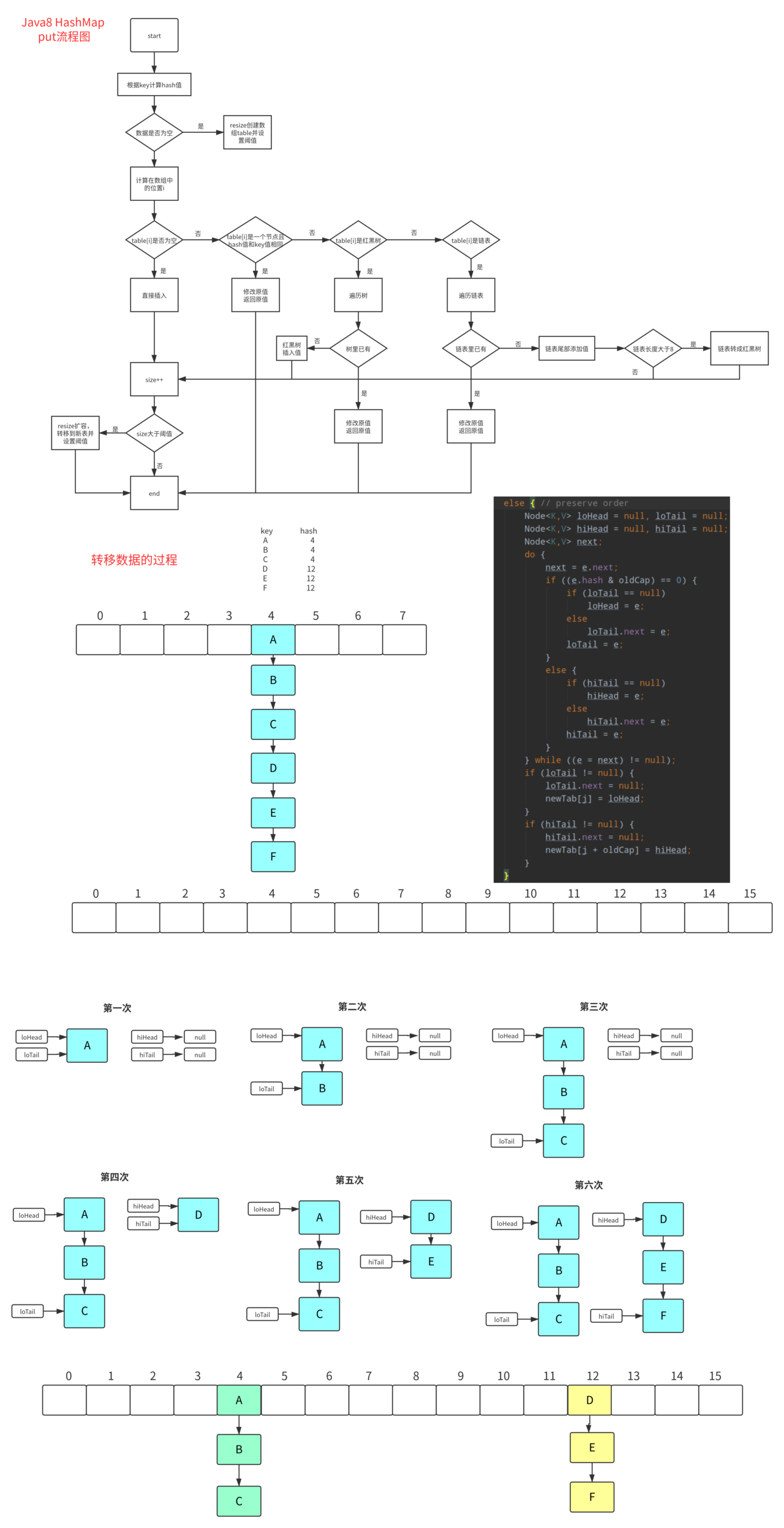
LinkedHashMap

特点:有序的 HashMap 速度快
- LinkedHashMap 是非线程安全的
- 可以把 LinkedHashMap 看成是 HashMap+LinkedList
- 使用 HashMap 操作数据结构,也用 LinkedList 维护插入元素的先后顺序
LinkedHashMap 底层
- 哈希表 + 双向链表
TreeMap
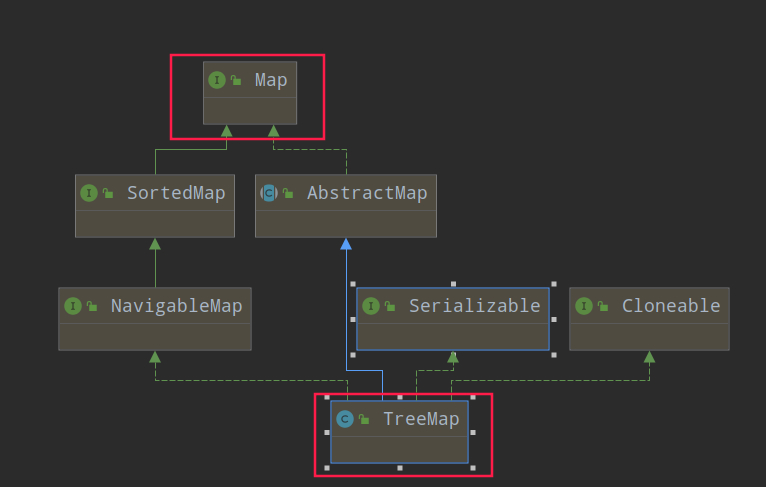
有序 速度没有 hash 快
问题:Set 与 Map 有关系吗?
如果集合前缀相同,底层算法一样,Set 底层用的是 Map 的算法.
把 Set 集合对象作为 Map 的 Key,再使用一个 Object 常量作为 value.
也就是说,在 Map 中,所有的 Key 就是一个 Set 集合.
iterator 接口
所有实现了 Collection 接口的容器类都有一个 iterator 方法用以返回一个实现了 Iterator 接口的对象
iterator 是一个接口,它是集合的迭代器。集合可以通过 Iterator 去遍历集合中的元素。
所有的集合类均为提供相应的遍历方法,而是把遍历交给迭代器完成.迭代器是为集合而生,专门实现集合遍历
Iterator 是迭代器设计模式的具体实现.
有些新手更疑惑了,啥是迭代器?
Provide a way to access the elements of an aggregate object sequentially without exposing its
underlying representation.它提供一种方法访问一个容器对象中各个元素, 而又不需暴露该对象的内部细节。
下图是迭代器模式通用类图

迭代器就是为容器服务的.
迭代器模式提供了遍历容器的方便性, 容器只要管理增减元素就可以了, 需要遍历时交
由迭代器进行。
简单地说, 迭代器就类似于一个数据库中的游标, 可以在一个容器内上下翻滚, 遍历所
有它需要查看的元素
可以使用 Iterator 的本质就是实现了 Iterator 接口
Iterator 提供的 API 接口如下:

在 iterator()方法中,要求返回一个 Iterator 的接口子类实例对象,此接口包含了 hasNext(),next(),remove()
boolean hashNext();//判断是否有元素没有被遍历
Object next();//返回游标当前位置的元素并将游标移动到下一个位置
void remove();//删除游标左面的元素,在执行完next之后该操作只能执行一次
在使用 Iterator 进行迭代过程中,如果删除其中的某个元素会报错----> 并发操作异常.
如果只删除一个元素可以使用 remove 方法删除,因为 remove 只可以被调用一次
java 中的 For-each 循环
For-each 循环
-
增强的 for 循环,遍历 array 或 Collection 的时候相当简便
-
无需获得集合和数组的长度,无需使用索引访问元素,无需循环条件
-
遍历集合时底层调用 Iterator 完成操作
For-each 缺陷
- 数组:
- 不能方便访问下标值
- 不要在 for-each 中尝试对变量赋值,只是一个临时变量
- 集合
- 与使用 Iterator 相比,不能方便 的删除集合总的内容
- For-each 总结
- 除了简单的遍历并读出其中的内容外,不建议使用增强 for 循环(For-each)
- 数组:
ListIterator
为什么需要 ListIterator
在迭代过程中,准备添加或者删除元素
ArrayList al=new ArrayList();
al.add("java1");//添加元素
al.add("java2");
al.add("java3");
//遍历
Iterator it=al.iterator();
while(it.hasNext()){
Object obj=it.next();
if (obj.equals("java2")) {
al.add("java9");
}
System.out.println("obj="+obj);
}
提示并发修改异常
obj=java1
obj=java2
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at cn.xysycx.Test1.main(Test1.java:15)
Process finished with exit code 1
ListIterator 的作用---> 解决并发操作异常
在迭代时,不可能通过集合对象的方法(al.add(?))操作集合中的元素
会发生并发修改异常
所以,在迭代时只能通过迭代器的方法操作元素,但是 Iterator 的方法是有限的,只能进行判断(hasNext),取出(next),删除(remove)的操作,
如果想要在迭代过程中进行向集合中添加,修改元素等就需要使用 ListIterator 接口中的方法
ListIterator li=al.listIterator();
while(li.hasNext()){
Object obj=li.next();
if ("java2".equals(obj)) {
li.add("java9994");
// li.set("java002");
}
}
Comparable 接口
问题:如何排序?
上面的算法根据什么确定集合对象的"大小"顺序?
所有可以"排序"的了都实现了 java.lang.Comparable 接口
Comparable 接口中只有一个方法
public int compareTo(Object obj);
返回 0 表示 this == obj
返回 正数 表示 this > obj
返回 负数 表示 this < obj
实现了 Comparable 接口的类通过实现 compareTo 方法从而确定了该类的排序方式
排序方法示例代码如下
public class StrLenComparator implements Comparator<String> {
public int compare(String o1, String o2) {
if (o1.length()>o2.length()) {
return 1;
}
if (o1.length()<o2.length()) {
return -1;
}
return o1.compareTo(o2);//长度相同,按字母
}
}
public static void sortDemo(){
List<String> list=new ArrayList<String>();
//此处省略..添加元素
sop(list);
Collections.sort(list);//按字母排序
sop(list);
//按照字符串长度排序
Collections.sort(list,new StrLenComparator());
sop(list);
}
Collection 工具类
Collections 和 Collection 不同
Collections 是集合的操作类,Collection 是集合接口
Collections 提供的静态方法
- addAll(): 批量的添加
- sort():排序
- binarySearch():二分查找
- fill():替换
- shuffle():随机排序
- reverse():逆序
集合总结
| 名称 | 存储结构 | 顺序 | 唯一性 | 查询效率 | 添加/删除效率 |
|---|---|---|---|---|---|
| ArrayList | 顺序表 | 有序(添加) | 不唯一 | 索引查询效率高 | 低 |
| LinkedList | 链表 | 有序(添加) | 不唯一 | 低 | 最高 |
| HashSet | 哈希表 | 无序 | 唯一 | 最高 | 最高 |
| HashMap | 哈希表 | Key 无序 | Key 唯一 | 最高 | 最高 |
| LinkedHashSet | 哈希表 + 链表 | 有序(添加) | 唯一 | 最高 | 最高 |
| LinkedHashMap | 哈希表 + 链表 | Key 有序 | Key 唯一 | 最高 | 最高 |
| TreeSet | 二叉树 | 有序(升序) | 唯一 | 中等 | 中等 |
| TreeMap | 二叉树 | 有序(升序) | Key 唯一 | 中等 | 中等 |
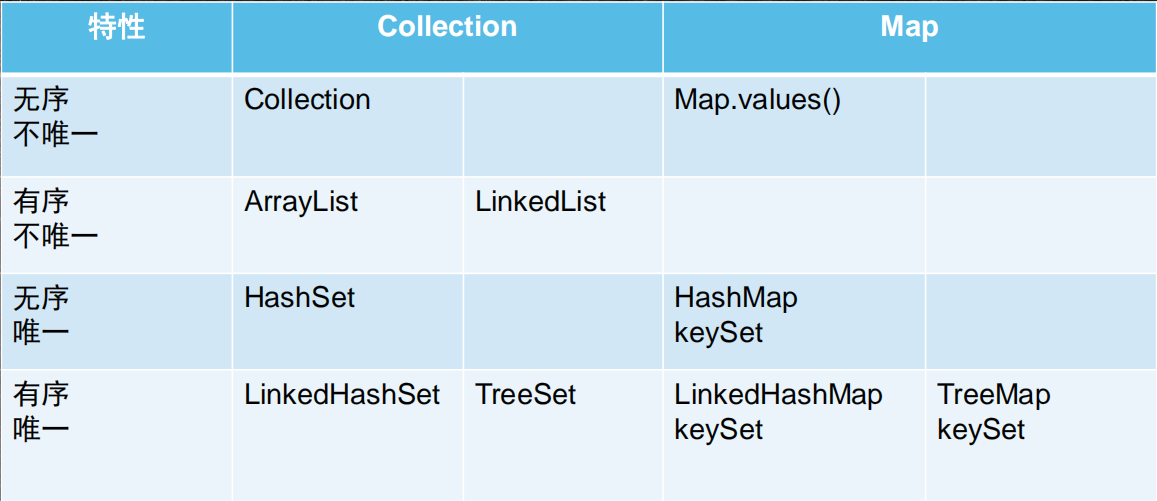
面试常问
Collection 和 Collections 的区别
- Collection 是 Java 提供的集合接口,存储一组丌唯 一,无序的
对象。它有两个子接口 List 和 Set。 - Java 还有一个 Collections 类,与门用来操作集合类,它提供了
一系列的静态方法实现对各种集合的搜索、排序、线程安全化
等操作。
ArrayList 和 LinkedList 的联系和区别
- ArrayList 实现了长度可变的数组,在内存中分配连续空间.遍历元素和随机访问元素效率比较高
- LinkedList 采用链表存储方式.插入、删除元素效率比较高
Vector 和 ArrayList 的联系和区别
- Vector 和 ArrayList 实现原理相同,都是长度可变的数组结构,很多时候可以互用
- 两者主要区别如下
- Vector 是早期 JDK 接口,ArrayList 是替代 Vector 的新接口
- Vector 线程安全,ArrayList 重速度轻安全,线程非安全
- 长度需要增长时,Vector 默认增长一倍,ArrayList 增长 50% (1+0.5)
HashMap 和 Hashtable 的联系和区别
- HashMap 和 HashTable 的实现原理相同,功能相同,底层都是 hash 表结构,查询速度快,在很多情况下都可以互用
- 两者主要区别如下
- HashTable 是早期的 JDK 提供的接口,HashMap 是新版的 JDK 提供的接口
- HashTable 继承 Dictionary 类,HashMap 实现 Map 接口
- HashTable 是线程安全,HashMap 是线程非安全
- HashTable 不允许 null 值,HashMap 允许 null 值
标题:Java容器类
作者:shuaibing90
版权声明:本站所有文章除特别声明外,均采用 CC BY-SA 4.0转载请于文章明显位置附上原文出处链接和本声明
地址:https://xysycx.cn/articles/2020/11/17/1605549124988.html
欢迎加入博主QQ群点击加入群聊:验证www.xysycx.cn
- 容器的概念
- 为什么要使用集合框架(Why)
- Java 集合框架包含的内容
- Collection 接口
- 添加
- 删除
- 查询
- 其它
- List 接口
- List 接口特有的方法
- ArrayList
- ArrayList 优点
- ArrayList 缺点
- ArrayList 面试问题
- LinkedList 采用链表存储方式
- linkedList 特有的方法
- LinkedList 优点
- LinkedList 缺点
- ArrayList 和 LinkedList 对比
- Set 接口
- 什么是 Hash 表
- HashSet
- 代码验证 HashSet 的无序性和唯一性
- hashSet 存储自定义对象
- HashSet 是如何保证元素的唯一性?
- LinkedHashSet
- TreeSet
- TreeSet 存放自定义类型示例代码
- TreeSet 优点
- TreeSet 缺点
- Map
- Map 接口特有的方法
- Map 的实现子类
- HashMap(重点)
- HashMap 底层
- LinkedHashMap
- LinkedHashMap 底层
- TreeMap
- 问题:Set 与 Map 有关系吗?
- iterator 接口
- java 中的 For-each 循环
- For-each 循环
- ListIterator
- 为什么需要 ListIterator
- ListIterator 的作用---> 解决并发操作异常
- Comparable 接口
- 问题:如何排序?
- Collection 工具类
- 集合总结
- 面试常问
- Collection 和 Collections 的区别
- ArrayList 和 LinkedList 的联系和区别
- Vector 和 ArrayList 的联系和区别
- HashMap 和 Hashtable 的联系和区别